Preprocessing and Training¶
Data preprocessing and model training for CSV¶
Load gene expression matrix and sample time information.
# %%
import pandas as pd
import scanpy as sc
import numpy as np
from anndata import AnnData
# Load the gene expression matrix and sample time information from a CSV file.
df = pd.read_csv('/lustre/home/2501111653/DeepRUOTv2_test_data/data/simulation_gene.csv')
# Create an observation DataFrame to store sample information.
obs = pd.DataFrame(index=df.index)
obs['samples'] = df['samples'].values
# Extract the gene expression matrix by dropping the 'samples' column.
X = df.drop(columns=['samples']).values
# Create an AnnData object from the gene expression matrix and observation DataFrame.
adata = AnnData(X=X, obs=obs)
# Save the AnnData object to an H5AD file for further analysis.
adata.write_h5ad('data/simulation_gene.h5ad')
Preprocess the data and train the model using the
ruot_simulation_geneconfiguration.
import CytoBridge as cb
# Preprocess the data with specified parameters.
adata = cb.pp.preprocess(adata, time_key='samples', dim_reduction='none', normalization=False, log1p=False, select_hvg=False)
# Train the model using the specified configuration and device.
adata = cb.tl.fit(adata, config='ruot_simulation_gene', device='cuda')
Using 'samples' as the time point identifier.
No time mapping provided. Generating automatic mapping.
Automatically generated time mapping: {0.0: 0, 1.0: 1, 2.0: 2, 3.0: 3, 4.0: 4}
Numerical time points stored in `adata.obs['time_point_processed']`.
Preprocessing recipe finished.
Loading built-in config: 'ruot_simulation_gene'
--- Starting Stage: Pretrain ---
Mode: neural_ode, Epochs: 100, Use Score: False
==== Pretrain ====
--------------------------------------------------
--------------------------------------------------
No scheduler parameters configured - keeping learning rate constant
velocity_net grad=True
growth_net grad=True
score_net grad=False
Optimizer parameters (shapes): [torch.Size([400, 3]), torch.Size([400]), torch.Size([400, 400]), torch.Size([400]), torch.Size([2, 400]), torch.Size([2]), torch.Size([400, 3]), torch.Size([400]), torch.Size([400, 400]), torch.Size([400]), torch.Size([1, 400]), torch.Size([1])]
Stage 'Pretrain', Epoch 1/100, Loss: 20.0579
[INFO] Epoch 0 has a lower loss| all_loss 20.0579
Stage 'Pretrain', Epoch 11/100, Loss: 47.3261
Stage 'Pretrain', Epoch 21/100, Loss: 34.2613
Stage 'Pretrain', Epoch 31/100, Loss: 23.4160
[INFO] Epoch 36 has a lower loss| all_loss 18.5398
[INFO] Epoch 38 has a lower loss| all_loss 17.8817
Stage 'Pretrain', Epoch 41/100, Loss: 19.3527
[INFO] Epoch 42 has a lower loss| all_loss 7.9504
[INFO] Epoch 43 has a lower loss| all_loss 4.3479
[INFO] Epoch 49 has a lower loss| all_loss 3.2200
Stage 'Pretrain', Epoch 51/100, Loss: 15.4235
[INFO] Epoch 52 has a lower loss| all_loss 2.6459
[INFO] Epoch 57 has a lower loss| all_loss 2.4091
Stage 'Pretrain', Epoch 61/100, Loss: 10.2236
Stage 'Pretrain', Epoch 71/100, Loss: 4.0316
[INFO] Epoch 73 has a lower loss| all_loss 1.6338
Stage 'Pretrain', Epoch 81/100, Loss: 15.7314
Stage 'Pretrain', Epoch 91/100, Loss: 14.1136
Best model (loss=1.6338) saved → /home/sjt/workspace2/CytoBridge_test-main_crufm/results/experiment_simulation/Pretrain/best.pth
--- Starting Stage: Train_FM ---
Mode: flow_matching, Epochs: 3000, Use Score: False
==== Train_FM ====
--------------------------------------------------
velocity_net grad=False
growth_net grad=False
score_net grad=True
Optimizer parameters (shapes): [torch.Size([128, 3]), torch.Size([128]), torch.Size([128, 128]), torch.Size([128]), torch.Size([128, 128]), torch.Size([128]), torch.Size([128, 128]), torch.Size([128]), torch.Size([1, 128]), torch.Size([1])]
alpha_regm : 1.0
Computing UOT plans...: 0%| | 0/4 [00:00<?, ?it/s]
Final entropic reg selected: 0.051000000000000004
Computing UOT plans...: 25%|██▌ | 1/4 [00:01<00:04, 1.62s/it]
Elbow rule selected reg_m: 1.125336
Time step 0 chunk 0 (per_time): reg=0.051000000000000004, reg_m=1.1253355826007645
Time step 0 chunk: scaled reg_m = 1.1253355826007645
Final entropic reg selected: 0.051000000000000004
Computing UOT plans...: 50%|█████ | 2/4 [00:03<00:03, 1.79s/it]
Elbow rule selected reg_m: 1.359356
Time step 1 chunk 0 (per_time): reg=0.051000000000000004, reg_m=1.3593563908785256
Time step 1 chunk: scaled reg_m = 1.3593563908785256
Final entropic reg selected: 0.051000000000000004
Computing UOT plans...: 75%|███████▌ | 3/4 [00:05<00:02, 2.03s/it]
Elbow rule selected reg_m: 0.931603
Time step 2 chunk 0 (per_time): reg=0.051000000000000004, reg_m=0.9316027658125524
Time step 2 chunk: scaled reg_m = 0.9316027658125524
Final entropic reg selected: 0.051000000000000004
Elbow rule selected reg_m: 6.162311
Time step 3 chunk 0 (per_time): reg=0.051000000000000004, reg_m=6.1623106765027
Time step 3 chunk: scaled reg_m = 6.1623106765027
Computing UOT plans...: 100%|██████████| 4/4 [00:09<00:00, 2.38s/it]
Flow matching: 100%|██████████| 3000/3000 [00:34<00:00, 86.44it/s]
Best model (loss=0.7355) saved → /home/sjt/workspace2/CytoBridge_test-main_crufm/results/experiment_simulation/Train_FM/best_model.pth
--- Starting Stage: Finetune ---
Mode: neural_ode, Epochs: 500, Use Score: False
==== Finetune ====
--------------------------------------------------
--------------------------------------------------
No scheduler parameters configured - keeping learning rate constant
velocity_net grad=True
growth_net grad=True
score_net grad=False
Optimizer parameters (shapes): [torch.Size([400, 3]), torch.Size([400]), torch.Size([400, 400]), torch.Size([400]), torch.Size([2, 400]), torch.Size([2]), torch.Size([400, 3]), torch.Size([400]), torch.Size([400, 400]), torch.Size([400]), torch.Size([1, 400]), torch.Size([1])]
Stage 'Finetune', Epoch 1/500, Loss: 1.0074
[INFO] Epoch 0 has a lower loss| all_loss 1.0074
[INFO] Epoch 1 has a lower loss| all_loss 0.6438
[INFO] Epoch 2 has a lower loss| all_loss 0.6264
[INFO] Epoch 3 has a lower loss| all_loss 0.4631
[INFO] Epoch 4 has a lower loss| all_loss 0.3114
[INFO] Epoch 5 has a lower loss| all_loss 0.2285
[INFO] Epoch 8 has a lower loss| all_loss 0.2060
[INFO] Epoch 9 has a lower loss| all_loss 0.1449
Stage 'Finetune', Epoch 11/500, Loss: 0.2533
[INFO] Epoch 12 has a lower loss| all_loss 0.1269
[INFO] Epoch 17 has a lower loss| all_loss 0.0989
Stage 'Finetune', Epoch 21/500, Loss: 0.1409
Stage 'Finetune', Epoch 31/500, Loss: 0.1737
Stage 'Finetune', Epoch 41/500, Loss: 0.1781
Stage 'Finetune', Epoch 51/500, Loss: 0.1484
Stage 'Finetune', Epoch 61/500, Loss: 0.3970
Stage 'Finetune', Epoch 71/500, Loss: 0.2611
Stage 'Finetune', Epoch 81/500, Loss: 0.4177
Stage 'Finetune', Epoch 91/500, Loss: 0.9225
Stage 'Finetune', Epoch 101/500, Loss: 0.5163
Stage 'Finetune', Epoch 111/500, Loss: 0.5112
Stage 'Finetune', Epoch 121/500, Loss: 0.7191
Stage 'Finetune', Epoch 131/500, Loss: 0.4168
Stage 'Finetune', Epoch 141/500, Loss: 0.3782
Stage 'Finetune', Epoch 151/500, Loss: 0.2921
Stage 'Finetune', Epoch 161/500, Loss: 0.3177
Stage 'Finetune', Epoch 171/500, Loss: 0.3197
Stage 'Finetune', Epoch 181/500, Loss: 0.2616
Stage 'Finetune', Epoch 191/500, Loss: 0.3278
Stage 'Finetune', Epoch 201/500, Loss: 0.5029
Stage 'Finetune', Epoch 211/500, Loss: 0.3042
Stage 'Finetune', Epoch 221/500, Loss: 0.2567
Stage 'Finetune', Epoch 231/500, Loss: 0.3887
Stage 'Finetune', Epoch 241/500, Loss: 0.3616
Stage 'Finetune', Epoch 251/500, Loss: 0.3389
Stage 'Finetune', Epoch 261/500, Loss: 0.5544
Stage 'Finetune', Epoch 271/500, Loss: 0.5364
Stage 'Finetune', Epoch 281/500, Loss: 0.5680
Stage 'Finetune', Epoch 291/500, Loss: 0.4629
Stage 'Finetune', Epoch 301/500, Loss: 0.2851
Stage 'Finetune', Epoch 311/500, Loss: 0.3818
Stage 'Finetune', Epoch 321/500, Loss: 0.6897
Stage 'Finetune', Epoch 331/500, Loss: 0.2598
Stage 'Finetune', Epoch 341/500, Loss: 0.3543
Stage 'Finetune', Epoch 351/500, Loss: 0.5957
Stage 'Finetune', Epoch 361/500, Loss: 0.6090
Stage 'Finetune', Epoch 371/500, Loss: 0.3244
Stage 'Finetune', Epoch 381/500, Loss: 0.3062
Stage 'Finetune', Epoch 391/500, Loss: 0.5577
Stage 'Finetune', Epoch 401/500, Loss: 0.4307
Stage 'Finetune', Epoch 411/500, Loss: 0.7193
Stage 'Finetune', Epoch 421/500, Loss: 0.4341
Stage 'Finetune', Epoch 431/500, Loss: 0.4636
Stage 'Finetune', Epoch 441/500, Loss: 0.3403
Stage 'Finetune', Epoch 451/500, Loss: 0.4383
Stage 'Finetune', Epoch 461/500, Loss: 0.4917
Stage 'Finetune', Epoch 471/500, Loss: 0.5931
Stage 'Finetune', Epoch 481/500, Loss: 0.2519
Stage 'Finetune', Epoch 491/500, Loss: 0.5036
Best model (loss=0.0989) saved → /home/sjt/workspace2/CytoBridge_test-main_crufm/results/experiment_simulation/Finetune/best.pth
['velocity', 'growth', 'score']
Model & data saved -> /home/sjt/workspace2/CytoBridge_test-main_crufm/results/experiment_simulation
--- Starting Evaluation ---
Time Point 1.0: Wasserstein-1 Distance = 0.0690
Time Point 1.0: TMV = 0.6013
Time Point 2.0: Wasserstein-1 Distance = 0.1551
Time Point 2.0: TMV = 0.6852
Time Point 3.0: Wasserstein-1 Distance = 0.3071
Time Point 3.0: TMV = 0.8264
Time Point 4.0: Wasserstein-1 Distance = 0.4316
Time Point 4.0: TMV = 1.0692
Plot the growth rate of the data.
cb.pl.plot_growth(adata, dim_reduction = 'none', output_path= '/home/sjt/workspace2/CytoBridge_test-main_crufm/figures/g_values_plot.svg')
[plot_growth] saved to -> /home/sjt/workspace2/CytoBridge_test-main_crufm/figures/g_values_plot.svg
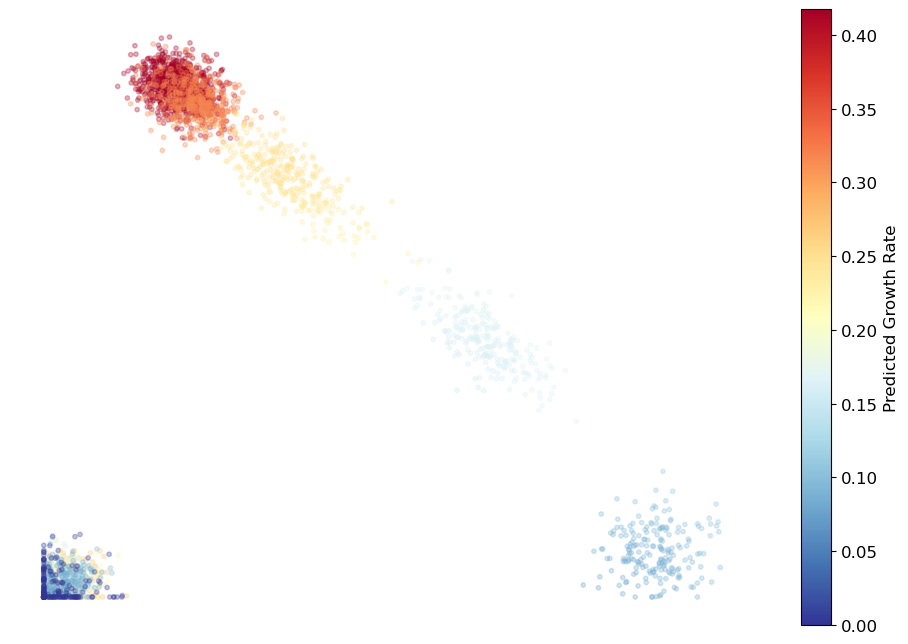
Data preprocessing and model training for h5ad¶
Load gene expression matrix and sample time information.
import scanpy as sc
adata = sc.read_h5ad('/home/sjt/workspace2/CytoBridge_test-main_crufm/data/weinreb_unpropocessed.h5ad')
adata
AnnData object with n_obs × n_vars = 49116 × 25289
obs: 'time_info', 'state_info', 'NeuMon_fate_bias', 'NeuMon_mask', 'progenitor_Ccr7_DC', 'progenitor_Mast', 'progenitor_Meg', 'progenitor_pDC', 'progenitor_Eos', 'progenitor_Lymphoid', 'progenitor_Erythroid', 'progenitor_Baso', 'progenitor_Neutrophil', 'progenitor_Monocyte', 'sp_500_idx', 'MLPClassifier_predicted_bias', 'growth_rate_raw', 'growth_rate_smooth'
uns: 'available_map', 'clonal_time_points', 'data_des', 'progenitor_Monocyte_colors', 'state_info_colors', 'time_ordering'
obsm: 'X_clone', 'X_emb', 'X_pca'
Specify the time key in
obsand preprocess the data.
import CytoBridge as cb
adata = cb.pp.preprocess(adata, time_key = 'time_info', dim_reduction = 'PCA', normalization = True, log1p = True, select_hvg = True)
Using 'time_info' as the time point identifier.
No time mapping provided. Generating automatic mapping.
Automatically generated time mapping: {'2': 0, '4': 1, '6': 2}
Numerical time points stored in `adata.obs['time_point_processed']`.
Normalizing total counts and applying log1p transformation.
Selecting top 2000 highly variable genes.
View of AnnData object with n_obs × n_vars = 49116 × 2000
obs: 'time_info', 'state_info', 'NeuMon_fate_bias', 'NeuMon_mask', 'progenitor_Ccr7_DC', 'progenitor_Mast', 'progenitor_Meg', 'progenitor_pDC', 'progenitor_Eos', 'progenitor_Lymphoid', 'progenitor_Erythroid', 'progenitor_Baso', 'progenitor_Neutrophil', 'progenitor_Monocyte', 'sp_500_idx', 'MLPClassifier_predicted_bias', 'growth_rate_raw', 'growth_rate_smooth', 'time_point_processed'
var: 'highly_variable', 'means', 'dispersions', 'dispersions_norm'
uns: 'available_map', 'clonal_time_points', 'data_des', 'progenitor_Monocyte_colors', 'state_info_colors', 'time_ordering', 'log1p', 'hvg'
obsm: 'X_clone', 'X_emb', 'X_pca'
/home/ubuntu/anaconda3/envs/DeepRUOTv2/lib/python3.10/site-packages/scanpy/preprocessing/_pca/__init__.py:385: ImplicitModificationWarning: Setting element `.obsm['X_pca']` of view, initializing view as actual.
adata.obsm[key_obsm] = X_pca
(49116, 50)
50
Created n_pc_adata with reduced dimension: 49116 samples × 50 dimensions
Original gene information stored in n_pc_adata.uns['original_gene_info']
Preprocessing recipe finished.
AnnData object with n_obs × n_vars = 49116 × 50
obs: 'time_info', 'state_info', 'NeuMon_fate_bias', 'NeuMon_mask', 'progenitor_Ccr7_DC', 'progenitor_Mast', 'progenitor_Meg', 'progenitor_pDC', 'progenitor_Eos', 'progenitor_Lymphoid', 'progenitor_Erythroid', 'progenitor_Baso', 'progenitor_Neutrophil', 'progenitor_Monocyte', 'sp_500_idx', 'MLPClassifier_predicted_bias', 'growth_rate_raw', 'growth_rate_smooth', 'time_point_processed'
var: 'dimension_type', 'explained_variance', 'cumulative_variance'
uns: 'available_map', 'clonal_time_points', 'data_des', 'progenitor_Monocyte_colors', 'state_info_colors', 'time_ordering', 'log1p', 'hvg', 'pca', 'original_gene_info'
obsm: 'X_clone', 'X_emb', 'X_pca', 'X_latent'
Display the processed time coordinates.
adata.obs['time_point_processed']
0 2.0
1 2.0
2 2.0
3 2.0
4 2.0
...
49111 2.0
49112 2.0
49113 2.0
49114 2.0
49115 2.0
Name: time_point_processed, Length: 49116, dtype: float64
Train the model using the
ruot_weinreb2configuration.
adata = cb.tl.fit(adata, config = 'ruot_weinreb2', device = 'cuda')
Loading built-in config: 'ruot_weinreb2'
--- Starting Stage: Pretrain ---
Mode: neural_ode, Epochs: 10, Use Score: False
==== Pretrain ====
--------------------------------------------------
--------------------------------------------------
No scheduler parameters configured - keeping learning rate constant
velocity_net grad=True
growth_net grad=True
score_net grad=False
Optimizer parameters (shapes): [torch.Size([400, 51]), torch.Size([400]), torch.Size([400, 400]), torch.Size([400]), torch.Size([50, 400]), torch.Size([50]), torch.Size([400, 51]), torch.Size([400]), torch.Size([400, 400]), torch.Size([400]), torch.Size([1, 400]), torch.Size([1])]
Stage 'Pretrain', Epoch 1/10, Loss: 523.3851
[INFO] Epoch 0 has a lower loss| all_loss 523.3851
[INFO] Epoch 1 has a lower loss| all_loss 428.3913
[INFO] Epoch 2 has a lower loss| all_loss 378.7752
[INFO] Epoch 7 has a lower loss| all_loss 346.4558
Best model (loss=346.4558) saved → /home/sjt/workspace2/CytoBridge_test-main_crufm/results/experiment_weinreb1/Pretrain/best.pth
--- Starting Stage: Train_FM ---
Mode: flow_matching, Epochs: 30, Use Score: False
==== Train_FM ====
--------------------------------------------------
velocity_net grad=False
growth_net grad=False
score_net grad=True
Optimizer parameters (shapes): [torch.Size([128, 51]), torch.Size([128]), torch.Size([128, 128]), torch.Size([128]), torch.Size([128, 128]), torch.Size([128]), torch.Size([128, 128]), torch.Size([128]), torch.Size([1, 128]), torch.Size([1])]
alpha_regm : 1.0
Computing UOT plans...: 0%| | 0/2 [00:00<?, ?it/s]
[Round-1 eps=5.000e-02] Failed: UserWarning: Numerical errors at iteration 901
Final entropic reg selected: 0.07100000000000001
Elbow rule selected reg_m: 1.125336
Time step 0 chunk 0 (per_time): reg=0.07100000000000001, reg_m=1.1253355826007645
Time step 0 chunk: scaled reg_m = 1.1253355826007645
Time step 0 chunk: scaled reg_m = 1.1253355826007645
Computing UOT plans...: 50%|█████ | 1/2 [00:49<00:49, 49.21s/it]
Time step 0 chunk: scaled reg_m = 1.1253355826007645
Final entropic reg selected: 0.051000000000000004
Elbow rule selected reg_m: 1.359356
Time step 1 chunk 0 (per_time): reg=0.051000000000000004, reg_m=1.3593563908785256
Time step 1 chunk: scaled reg_m = 1.3593563908785256
Time step 1 chunk: scaled reg_m = 1.3593563908785256
Time step 1 chunk: scaled reg_m = 1.3593563908785256
Time step 1 chunk: scaled reg_m = 1.3593563908785256
Time step 1 chunk: scaled reg_m = 1.3593563908785256
Time step 1 chunk: scaled reg_m = 1.3593563908785256
Time step 1 chunk: scaled reg_m = 1.3593563908785256
Time step 1 chunk: scaled reg_m = 1.3593563908785256
Computing UOT plans...: 100%|██████████| 2/2 [01:33<00:00, 46.72s/it]
Flow matching: 100%|██████████| 30/30 [00:03<00:00, 9.77it/s]
Best model (loss=0.6366) saved → /home/sjt/workspace2/CytoBridge_test-main_crufm/results/experiment_weinreb1/Train_FM/best_model.pth
--- Starting Stage: Finetune ---
Mode: neural_ode, Epochs: 5, Use Score: False
==== Finetune ====
--------------------------------------------------
--------------------------------------------------
No scheduler parameters configured - keeping learning rate constant
velocity_net grad=True
growth_net grad=True
score_net grad=False
Optimizer parameters (shapes): [torch.Size([400, 51]), torch.Size([400]), torch.Size([400, 400]), torch.Size([400]), torch.Size([50, 400]), torch.Size([50]), torch.Size([400, 51]), torch.Size([400]), torch.Size([400, 400]), torch.Size([400]), torch.Size([1, 400]), torch.Size([1])]
Stage 'Finetune', Epoch 1/5, Loss: 411.4681
[INFO] Epoch 0 has a lower loss| all_loss 411.4681
[INFO] Epoch 1 has a lower loss| all_loss 408.1792
[INFO] Epoch 2 has a lower loss| all_loss 375.0804
[INFO] Epoch 4 has a lower loss| all_loss 354.1136
Best model (loss=354.1136) saved → /home/sjt/workspace2/CytoBridge_test-main_crufm/results/experiment_weinreb1/Finetune/best.pth
['velocity', 'growth', 'score']
Model & data saved -> /home/sjt/workspace2/CytoBridge_test-main_crufm/results/experiment_weinreb1
--- Starting Evaluation ---
Time Point 1.0: Wasserstein-1 Distance = 7.2566
Time Point 1.0: TMV = 36.7032
Time Point 2.0: Wasserstein-1 Distance = 8.7752
Time Point 2.0: TMV = 113.5138
Display the latent space representation of the data.
adata.obsm['X_latent']
array([[-3.6428378 , 2.436678 , -2.9170516 , ..., -0.611192 ,
-0.18371896, -0.6149843 ],
[-4.9441824 , -4.6696796 , 4.238613 , ..., -0.21018225,
0.48122397, 0.59066844],
[ 4.527339 , -0.30856872, -2.3583496 , ..., 0.56100917,
0.2844135 , -0.20859115],
...,
[ 2.555032 , 3.0457778 , -0.16068852, ..., 1.0851277 ,
-1.1630424 , 0.11137625],
[10.0182 , -6.800205 , -3.480523 , ..., 0.12070175,
-0.5067553 , -1.1749583 ],
[-3.3989573 , 2.264593 , -3.548077 , ..., -0.97040135,
0.39139208, -0.32629538]], dtype=float32)
Display the updated AnnData object.
adata
AnnData object with n_obs × n_vars = 49116 × 50
obs: 'time_info', 'state_info', 'NeuMon_fate_bias', 'NeuMon_mask', 'progenitor_Ccr7_DC', 'progenitor_Mast', 'progenitor_Meg', 'progenitor_pDC', 'progenitor_Eos', 'progenitor_Lymphoid', 'progenitor_Erythroid', 'progenitor_Baso', 'progenitor_Neutrophil', 'progenitor_Monocyte', 'sp_500_idx', 'MLPClassifier_predicted_bias', 'growth_rate_raw', 'growth_rate_smooth', 'time_point_processed'
var: 'dimension_type', 'explained_variance', 'cumulative_variance'
uns: 'available_map', 'clonal_time_points', 'data_des', 'progenitor_Monocyte_colors', 'state_info_colors', 'time_ordering', 'log1p', 'hvg', 'pca', 'original_gene_info', 'all_model'
obsm: 'X_clone', 'X_emb', 'X_pca', 'X_latent', 'velocity_latent', 'growth_rate', 'score_latent'
Plot the growth rate using UMAP dimensionality reduction.
cb.pl.plot_growth(adata, dim_reduction = 'umap', output_path = 'g_values_plot.svg')
